El código abierto frente a la IA patentada: el restaurante frente a la comida casera
Ahora que entendemos qué es un LLM, surge una pregunta crucial: ¿quién los fabrica y cómo podemos usarlos? En el mundo de la IA, hay dos filosofías principales, dos formas diferentes de crear y compartir estas poderosas herramientas. Esta es la diferencia entre los modelos propietarios y de código abierto.
Para entender esto, usemos una analogía sencilla: conseguir una comida.
- La IA patentada es como ir a un restaurante de alta gama. Vas a un establecimiento de confianza (como OpenAI, Google o Anthropic). No conoces la receta secreta, no puedes ir a la cocina y no puedes cambiar la forma en que se hace el plato. Solo tiene que pedir de un menú (utilice su API) y un equipo de chefs profesionales le ofrecerá una comida refinada y de alta calidad. Es fácil, confiable y obtienes resultados de primera categoría, pero cuesta dinero y estás limitado a lo que ofrecen.
- La IA de código abierto es como recibir la receta de un chef de primera categoría y la llave de una despensa completamente surtida. Una empresa (como Meta con sus modelos Llama o Mistral AI) desarrolla una receta increíble (el modelo AI) y luego la regala al público. Puedes ver cada ingrediente y cada paso. Puedes tomar la receta, llevarla a tu propia cocina (tu propio ordenador o servidor) y cocinarla tal cual. Mejor aún, puedes modificarla: añadir un poco de sabor, cambiar un ingrediente o ampliarla para alimentar a una familia numerosa. Te da una libertad y un control increíbles, pero necesitas las habilidades y la cocina para hacerlo tú mismo.
Ninguno de los dos enfoques es universalmente «mejor»: simplemente son modelos diferentes para necesidades diferentes, y ambos impulsan la innovación de maneras increíbles.
El código propietario frente al código abierto, de un vistazo
Analicemos las ventajas y desventajas. Elegir el tipo correcto de modelo de IA depende de lo que más valore: la comodidad, el control, el coste o un rendimiento de vanguardia.
Modelos patentados (The Restaurant)
Ejemplos: la serie GPT de OpenAI, Gemini de Google, Claude de Anthropic.
- Facilidad de uso: empezar es increíblemente sencillo. Solo tienes que registrarte y usarlo a través de un sitio web o una API simple. No se requiere una configuración compleja.
- Máximo rendimiento: estos modelos suelen ser los más potentes y capaces del mercado, ya que se invierten miles de millones de dólares en su desarrollo.
- Fiabilidad y soporte: cuentan con un soporte profesional y dedicado y con la confiabilidad de una gran corporación que mantiene el servicio.
- Costo: puede resultar caro. Por lo general, se paga por lo que se consume, y los costes pueden acumularse rápidamente para los usuarios habituales.
- Falta de transparencia: son «cajas negras». No sabes exactamente con qué datos fueron entrenados ni cómo se ajusta su funcionamiento interno.
- Confianza en un proveedor: depende de una sola empresa. Si cambian sus precios, políticas o interrumpen un servicio, tiene pocos recursos.
Modelos de código abierto (la receta)
Ejemplos: la serie Llama de Meta, los modelos Mistral, Falcon.
- Control y personalización: tienes el control total. Puede modificar el modelo para una tarea específica, ajustarlo a sus propios datos privados y ejecutarlo en cualquier lugar.
- Transparencia: la arquitectura y los «pesos» (sus parámetros aprendidos) del modelo están abiertos a la inspección, lo cual es importante para la investigación y la rendición de cuentas.
- Rentables a gran escala: si bien requieren una inversión inicial en hardware y experiencia, su descarga y uso son gratuitos, lo que evita gastos recurrentes.
- Complejidad: requiere una gran experiencia técnica para configurarla, mantenerla y optimizarla. No se trata de una solución simple «enchufar y usar».
- El soporte está basado en la comunidad: no hay una línea de soporte dedicada. Confías en los foros de la comunidad y en la capacidad de tu propio equipo para resolver problemas.
- Posible uso indebido: dado que cualquier persona puede acceder a ellos, existe un mayor riesgo de que personas malintencionadas utilicen estos modelos con fines malintencionados, como generar información errónea.
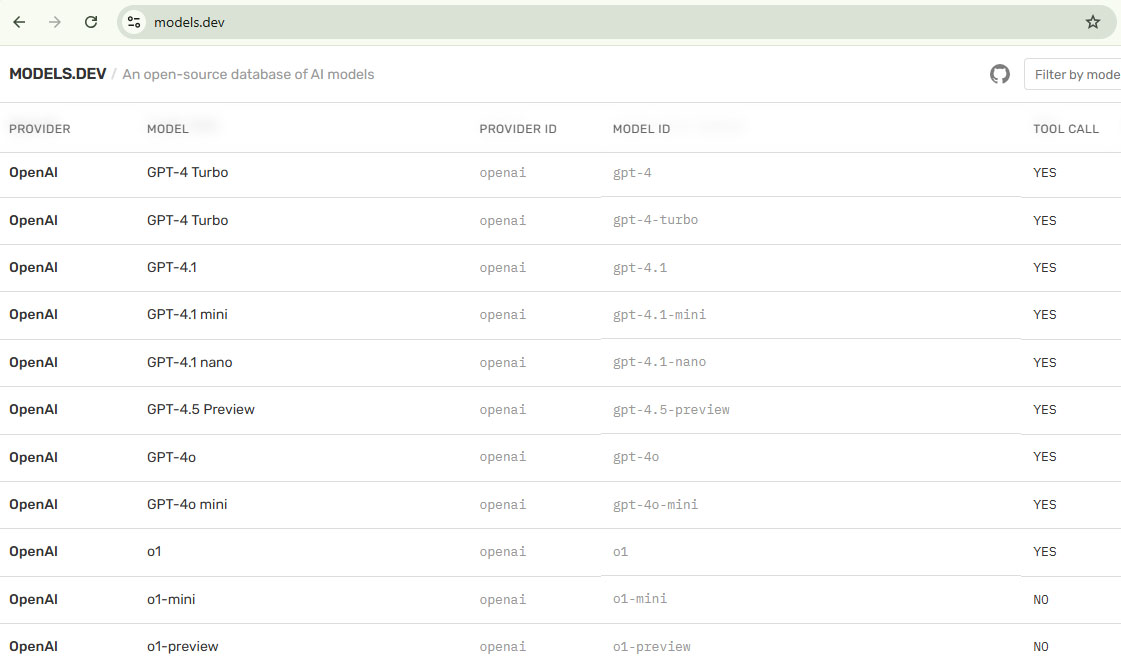
models.dev: Lista de Todos los Modelos de IA
Models.dev es una base de datos de código abierto exhaustiva de especificaciones, precios y características de modelos de IA.
Comprobación rápida
Un laboratorio de investigación universitario quiere analizar y modificar el funcionamiento interno de un modelo de IA para realizar un estudio sobre el sesgo de la IA. ¿Qué tipo de modelo sería el más adecuado para ellos?
Resumen: modelos de IA de código abierto frente a modelos patentados
Lo que cubrimos:
- Los modelos de IA se ofrecen principalmente de dos formas: propietarios (cerrados, como un restaurante) y de código abierto (públicos, como una receta).
- Los modelos patentados ofrecen facilidad de uso y un rendimiento máximo, pero tienen un coste y ofrecen menos transparencia.
- Los modelos de código abierto ofrecen control, personalización y transparencia, pero requieren experiencia y recursos técnicos.
- La elección entre ellos depende de sus necesidades, recursos y objetivos específicos.
Por qué es importante:
- Esta distinción es fundamental para el futuro de la IA. Afecta a todo, desde la forma en que las empresas crean productos de IA hasta la forma en que los investigadores individuales pueden innovar. Comprender este panorama le ayuda a ver quién tiene el poder y hacia dónde se dirigirá la tecnología a continuación.
El siguiente paso:
- Con todas las asombrosas afirmaciones sobre la IA, puede resultar difícil saber qué es verdad. En nuestra próxima lección, abordaremos algunos conceptos erróneos comunes y separaremos los mitos de la IA de la realidad.